AI大模型对算力爆发式的增长需求,正推动算力集群迈入“万卡协同”时代,但目前大多数AI算力集群都面临带宽、算力资源浪费等瓶颈,造成数据洪流下的网络交通拥堵,大大降低模型训练和推理效率。我们依托行业领先的光电芯片和互连技术,推出可显著提升带宽、降低时延并减少功耗的光互连电交换超节点方案光跃LP64和国内首个光互连光交换超节点方案光跃超节点 OP32。
行业困境
-

算力需求增长
-

带宽、算力资源浪费
-

洪流下的网络交通拥堵
-

模型训练和推理效率降低
光跃超节点 LP64 方案概述
光跃超节点 LP64光互连电交换超节点,采用线性直驱光互连技术,具备低延时、高带宽、低功耗的显著优势,支持长距离传输,有效突破跨机柜连接限制。该方案可实现8台标准服务器共64张xPU卡的高速互连,为大模型训练与推理提供更灵活、更高效的并行策略支持,从而显著提升集群整体性能。
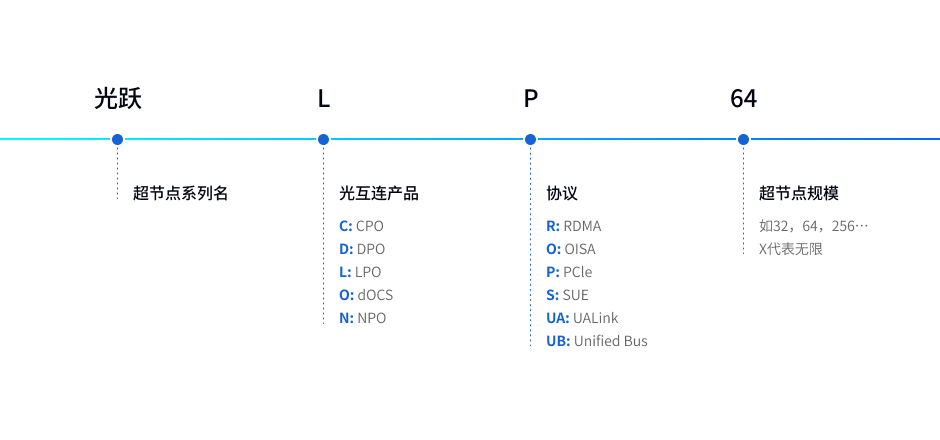
超节点命名规范
视频展示

关键技术
-

线性直驱光互连技术
-

低延时、高带宽、低功耗
-

支持长距离传输


方案亮点
-



极致性能表现
-


部署敏捷
-


跨服务器跨机柜直连
方案产品系列